PR-2 / CoTTA : Continual Test-Time Domain Adaptation
Abstract
Test-time domain adaptation은 소스 데이터를 사용하지 않고 사전 학습된 소스 모델을 대상 도메인에 적응시키는 것을 목표로 한다.
기존 연구에서는 주로 대상 도메인이 정적인(static) 경우를 주로 고려했습니다. 그러나 현실 세계의 기계 인식 시스템은 대상 도메인 분포가 시간에 따라 변할 수 있는 비정상적이고 지속적으로 변화하는 환경에서 돌아갑니다.
자가 학습 및 엔트로피 정규화를 기반으로 하는 대부분의 기존 방법은 이러한 비정상 환경으로 인해 어려움을 겪을 수 있습니다. 대상 도메인에서 시간에 따른 Distribution shift로 인해 pseudo-labels을 사용할 수 없게되었다. Noisy pseudo-labels가 생기면 오히려 Error accumulation과 Catastrophic forgetting을 야기할 수 있기 때문이다.
본 논문은 이러한 문제를 해결하고자 연속적인 테스트 단계 적응 기법인 CoTTA를 제안하며, 크게 다음 두 가지로 나뉨
- Weight-averaged and Augmentation averaged predictions
- To reduce Error accumulation, even more accurate.
- Stochastically Restoration
- To preserve source knowledge in the long-term
- To avoid catastrophic forgetting
제안하는 기법은 네트워크 모든 파라미터에 대해 장기 적응을 가능하게 한다.
(근데 다른 말로 하면 모든 파라미터를 업데이트함으로서 Comuptation cost가 매우 증가하여 적응까지 오래 걸림)
Introduction
소스 훈련 데이터와 타겟 테스트 데이터 사이 Domain-shift로 인해 좋은 성능을 내려면 적응이 필요합니다.
- (Semantic segmentation) 깨끗한 날씨 환경에서 사전 학습된 모델은 눈오는 저녁과 같은 환경에서 상당한 성능 저하(deterioration)가 생기게 됨.
- (Image classification) 사전 학습된 모델은 센서의 성능 차이(저하)로 인해 손상된 이미지에서 테스트할 때 동일한 현상을 겪을 수 있음.
여기서는 프라이버시 문제나 법적인 제약 때문에 소스 데이터는 보통 추론 단계에서 사용할 수 없다고 보기 때문에 비지도 도메인 적응 사례보다 더 어렵지만 현실적인 문제 상황으로 가정합니다. 다양한 시나리오에서 적응은 온라인 방식으로 이뤄져야 하므로, Test-time Adaptaion은 Domain-shift 시 실제 기계 인식 분야에서 성공하는 게 중요하다고 봅니다.
Self-training 방법은 동일한 정적 도메인에서 테스트 데이터를 가져올 때나 효과적입니다. Target의 테스트 데이터가 지속적으로 변하는 환경에서는 매우 불안정할 수 있습니다. [ref.SENTRY] 이에 기여하는 두 가지 측면이 있습니다.
- 지속적으로 변하는 환경에서 의사 레이블은 distribution-shift로 인해 노이즈가 심해지고 잘못 보정되므로 초기 예측 실수로 인해 오류가 누적될 가능성이 더 높다.
- 모델이 오랜 기간 동안 새로운 분포에 대해 지속적으로 적응함에 따라 소스 도메인의 지식을 보존하기가 더 어려워지고, 이는 결국 Catastrophic forgetting으로 이어진다.
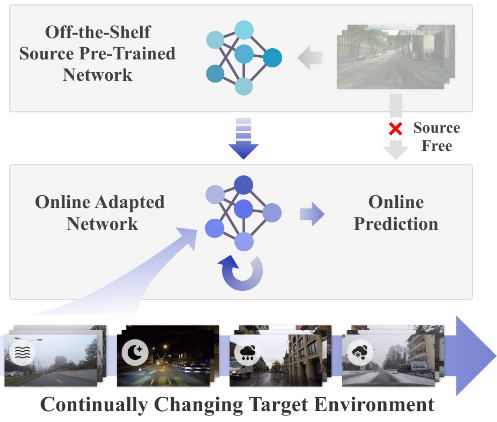
- Off-the-shelf source pre-trained network
- Target network를 초기화하기 위해 사용되며, 모델은 현재 타겟 데이터를 기반으로 online-update된다.
- 타겟 네트워크는 소스 데이터에 의존하지 않는다.
- 기존 방법은 Error Accumulation과 Catastrophic Forgetting으로 인해 시간이 지남에 따라 성능이 저하되는 경우가 많으나 저자의 방법은 지속적으로 변화하는 환경에서도 장기적인 TTA를 가능하게 한다.
계속 변화하는 환경에서 생기는 이런 문제들을 해결하기 위해 Online Continual Test-time adaptation의 실제 문제에 중점을 두기로 합니다. 그림에서 보듯 목표는 Off-the-shelf의 사전 학습된 소스 모델에서 시작하여 이를 현재 테스트 데이터에 지속적으로 적용하는 것입니다.
여기서 prediction과 update는 모두 online으로 동작합니다. 즉, 모델은 전체 테스트 데이터나 소스 데이터에 액세스할 수 없고, 현재 데이터 스트림에만 접근할 수 있습니다. 좀 더 풀어서 말하면 입력 시 들어오는 전체 테스트 데이터에 접근하지 않고 배치 단위로 쪼개어 들어오는 테스트 데이터만 사용하는 것입니다. 충분히 실제 기계 인식 시스템 상황과 유사하다고 봅니다. 가령, 자율 주행에서 주변 환경은 지속적으로 바뀌는데, 날씨가 맑았다가 구름이 끼고 나서 후에 비가 내리는 시나리오가 있을 것이며, 차량이 터널을 통과하는 순간 카메라 입력이 급격하게 바뀌는 시나리오도 있을 겁니다. 인식 모델은 이렇듯 정적이지 않은, non-stationary domain shifts에 따라 스스로 적응하고 Online으로 결정을 내려야 합니다.
사전 학습된 소스 모델을 지속적으로 변하는 테스트 데이터에 효과적으로 적응시키기 위해 CoTTA를 제안했습니다.
- 첫번째 목표는 error accumulation을 제거하는 것으로 자가 학습 프레임워크 하에 의사 레이블의 성능을 향상시키고자 합니다. Mean-teacher 모델이 일반 모델보다 더 좋은 퀄리티를 낸다는 점에서 착안하여, 더 정확한 예측을 내는 (1) Weight-averaged teacher model을 제안합니다. 도메인 차이가 더 큰 테스트 데이터의 경우 의사 레이블의 품질을 더욱 향상시키도록 하는 (2) Augmentation-averaged predictions을 제안합니다.
- 두번째 목표는 소스 지식을 망각하지 않고 유지하기 위해, 네트워크에 있는 뉴런의 작은 부분을 미리 훈련된 소스 모델로 Stochastically restoration하는 것을 제안합니다.
Error accumulation을 줄이고 지식을 보존함으로서 CoTTA는 지속적으로 변하는 환경에서도 장기 적응을 가능하게 합니다. 더불어 배치 정규화 파라미터만 train할 수 있는 기존 방법과는 달리 네트워크의 모든 파라미터를 train할 수 있습니다.
- 여기서 기존 방법으로 Confidence Maximization, Input transfromation 및 TENT, Entropy Minimization을 언급함
weight-and-augmentation-averaged 전략과 stochastic restoration은 소스 데이터를 다시 훈련시키기 않고도 어떠한 off-the-shelf pre-trained model에 쉽게 적용할 수 있다.
정리하자면,
- Continual Test-time Approach를 제안한다.
- Error Accumulation을 줄이기 위해 Weight-and-Augmentation-averaged pseudo-labels를 제안한다.
- Long-term Forgetting 효과를 제거하기 위해 소스 지식을 보존할 수 있는 Stochastically Resotration을 제안한다.
Related Work

2.2 Test-time Adaptation
Test-time adaptation은 source-free domain adaptation과 관련이 있습니다. 적응을 위해 소스와 타겟 도메인에 접근할 필요가 있는 기존 Domain adaptation과는 달리 TTA는 소스 도메인에 접근할 필요가 없습니다. 몇몇 연구는 도메인 정렬을 명시적으로 수행하지 않고, 소스 모델을 Fine-tune하기도 합니다.
- Test entropy minimization (TENT) : 사전 학습된 모델을 취하고 entropy minimization을 사용하여 Batchnorm 레이어의 훈련 가능한 매개변수를 업데이트하여 테스트 데이터에 적응함
- Source hypothesis transfer (SHOT) : 적응을 위해 entropy minimization과 diversity regulaizer를 동시에 사용함
- 이 모델은 임의의 사전 훈련된 모델을 사용할 수 없음.
- 그 외 기타 등등..
표준 TTA는 훈련을 위해 전체 테스트 데이터 셋에 대한 액세스가 제공되는 Offline 시나리오를 취급하며, 대부분의 기존 작업 (TENT 변형 모델들은 제외)은 TTA를 지원하기 위해 소스 모델을 재학습하는 것도 필요하기 때문에 소스 도메인에서 직접적으로 off-the-shelf pre-trained model을 사용할 수는 없다.
2.3 Continuous Domain Adaptation (CDA)
구체적인 타겟 도메인이 설정되어 있는 일반적인 Domain adaptation과는 달리 CDA는 지속적으로 변하는 타겟 데이터에서의 적응 상황을 고려합니다. 기존 방법론들은 분포 정렬을 위해 소스 도메인과 타겟 도메인에 전부 접근이 필요하지만, 본 논문은 소스 데이터에 접근하지 않고 테스트 단계에서 적응하는 것에 초점이 맞춰져 있습니다.
TENT-Online도 entropy loss를 사용하여 BN 파라미터를 계속 업데이트하면 이런 시나리오에서도 적응을 할 수는 있습니다. 그러나 잘못 보정된 예측으로 인해 오류가 누적될 수 있습니다. Test-time training(TTT)도 rotation prediction auxiliary task로부터 supervision을 사용하여 특징 추출기를 지속적으로 업데이트 할 수 있습니다. 다만, 이러한 보조 작업을 학습하려면 소스 데이터를 사용하여 소스 모델을 재학습 시켜야하기 때문에 전체 파이프라인으로 볼 때, source-free로 간주할 수 없습니다. 그리고 off-the-shelf source pre-trained models 역시 지원하지 않고요.
2.5 Domain Generalization (DG)
(이 부분은 논문과 좀 다르게 정리)
두 방식 모두 도메인 간 변화에 대처하기 위한 접근 방식이나 명확한 차이점이 있다.
Domain Generalization은 훈련 중에 본 적 없는 새로운 도메인에 대해 잘 수행할 수 있도록 하는 것이 목표입니다. 이는 훈련 데이터로부터 도메인에 구애받지 않는 일반적인 특징을 학습하여, 모델이 다양한 도메인에서도 안정적인 성능을 발휘할 수 있도록 합니다. DG는 테스트 단계에서 모델이 추가적인 적응을 하진 않습니다.
반면에, CTTA는 모델에 테스트 단계에서 데이터가 지속적으로 변화하는 환경에 적응하도록 하는 방식이기 때문에 모델은 테스트 데이터 스트림을 처리하면서 실시간을 정보를 업데이트하고 새로운 도메인 특징을 학습하게 됩니다. 핵심은 모델이 새로운 데이터에 빠르게 적응하면서 이전 데이터에서 배운 유용한 정보(지식)을 유지할 수 있도록 하는 것입니다.
요약하자면, 도메인 일반화는 모델이 다양한 도메인에 걸쳐 일반적인 특징을 학습하여 새로운 도메인에 직면했을 때 바로 적용할 수 있도록 하는 반면, CTTA는 모델에 테스트 단계에서 지속적으로 데이터 변화에 적응하도록 함으로써, 도메인의 변화에 더 유연하게 대응할 수 있게 합니다.
CONTINUAL TEST-TIME DOMAIN ADAPTATION
3.1 PROBLEM DEFINITION
목표 : Improving the performance of existing model during inference time for a continually changing target domain in an online fashion without having access to any source data.
- existing pre-trained model : `f_{\theta_{0}}(x)` with parameters `\theta`
- Unlabeled target domain data : `X^T` is provided sequentially
- At time step `t`, target data `x_t^T` as input
- 각 시간 단계 `t`에서 모델은 새로운 타겟 도메인 데이터 `x _t ^T`를 받는다.
- the model `f_{\theta_t}` `\to` the prediction `f_{\theta_t}(x _t ^T)`
- 모델 f_{\theta_t}는 현재 매개변수 θ_t를 사용하여 입력 데이터 x^T_t의 예측 f_{\theta_t}(x _t ^T)을 수행함
- 예측 후, 모델은 새로운 데이터 x _t ^T에 기반하여 매개변수 θ_t를 업데이트
- adapts itself accordingly for future inputs `\theta_t \to \theta_{t+1}`
- 모델이 현재 데이터 x _t ^T에 대한 예측을 기반으로 매개변수 θ_t를 θ_{t+1}로 업데이트하여 미래의 입력 데이터에 더 잘 적응하도록 한다
- [참고] 모델이 스스로 적응한다는 말은 시간이 지남에 따라 들어오는 새로운 타겟 도메인 데이터 `x _{t+1} ^T`에 대해 모델의 매개변수 `\theta`를 동적으로 업데이트하여 모델의 예측 성능을 향상시킨다는 것을 의미함
- target data `x _t ^T`의 distribution이 지속적으로 변하는 중임
- 모델은 online predicitons를 기반으로 평가를 진행한다.
3.2 METHODOLOGY
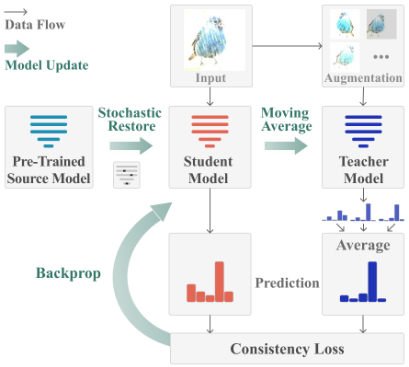
- 가중치 평균 의사 레이블을 제공하기 위해 교사 모델을 사용하고, 예측을 평균화하기 위해 여러 Augmentation을 사용하여 오류 누적을 완화시킨다.
- 소스 데이터의 지식은 학습 가능한 가중치의 일부 요소를 확률적으로 복원하여 보존한다.
error accumulation은 자가학습 프레임워크의 주요 병목 현상 중 하나라는 사실에 동기를 받아, 가중치 및 증강 평균 의사 레이블을 사용하여 에러 축적을 감소하는 방안을 제안한다. 그리고 Continual-Adaptation에서 망각을 줄이기 위해 소스 모델의 정보를 명시적으로 보존할 것을 제안한다.
여기서 말하는 off-the-shelf는 말 그대로 바로 사용가능한 pre-trained model을 의미한다. 아마도 소스 데이터에 접근해야하는 다른 방법론들과의 대비를 위해 사용한 용어같다. 말은 즉슨, 다른 방법론들과 달리 본 논문의 TTA 알고리즘은 네트워크 구조를 변경할 필요도 없으며 추가 소스 데이터 훈련 과정을 요구하지 않기 때문에 소스에 대한 재학습 없이 모델을 바로 사용할 수 있다는 말이다.
Weight-Averaged Pseudo-Labels
self-traing 프레임워크를 사용하는 일반적인 test-time 목표는 예측값 `\hat y^T_t`와 pseudo-label 사이 cross-entropy consistency를 최소화하는 것입니다. 예를 들면 TENT의 entropy minimization을 들 수 있는데, 이는 정적인 대상 도메인에 대한 것이 때문에 지속적으로 변하는 대상 데이터의 경우 의사 레이블의 품질이 크게 떨어질 수 있습니다.
훈련 과정에서 가중치 평균이 적용된 모델이 최종 모델보다 더 정확한 모델을 만드는 경향이 있음을 발견하여 다음 과정을 제안합니다.
- Weight-averaged teacher model `f_{\theta'}`를 사용하여 pseudo-labels를 만듦
- time step `t=0`에서 teacher model은 source pre-trained model로 초기화됨
- teacher \hat y'_t ^T=f_{\theta'_t}(x _t ^T)로부터 pseudo-label이 최초로 생김
- student `f_{\theta_t}는 교사와 학생 예측값 사이 cross-entropy를 사용하여 업데이트되어 둘 사이 consistency를 강화한다.
- student model update
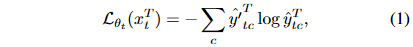
- student model update
- student `f_{\theta_t}는 교사와 학생 예측값 사이 cross-entropy를 사용하여 업데이트되어 둘 사이 consistency를 강화한다.
- 식 (1)을 통해 student model `\theta_t \to \theta_{t+1}`로 업데이트가 되면, student 가중치로 Exponential moving average를 계산하여 teacher model의 가중치도 업데이트한다.
- teacher model update
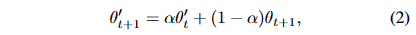
- teacher model update
The benefits of the weight-averaged consistency
우선 계속 똑같은 말만 하고 있지만.. 논문이 다 그렇지..
- 더 정확한 가중치 평균 예측을 의사 라벨 목표로 사용함으로써 모델은 지속적인 적응 동안 오류 누적으로 인한 영향을 덜 받는다.
- 평균 교사 예측 `\hat y' _t ^T`는 과거 반복에서 모델의 정보를 인코딩하므로 장기 연속 적응에서 치명적인 망각으로 고통받을 가능성이 줄어들고, 새로운 보지못한 도메인에 대한 일반화 능력이 개선된다.
Augmentation-Averaged Pseudo-Labels
훈련 단계에서 데이터 증강은 이미 모델 성능 개선을 위해 많이들 사용하고 있습니다. Different augmentation이란 것도 있구요. test-time augmentation도 강인함을 향상시킬 수 있는 것으로 입증되었지만, Augmentation 전략은 일반적으로 추론 시간 동안의 분포 변화를 고려하지 않고 특정 데이터 셋에 대해 결정되고 수정되기 마련입니다.
특히나 지속적으로 변화하는 환경에서 테스트 분포가 크게 변경될 수 있어서 데이터 증강이 소용 없어질 수 있습니다. 여기서는 테스트 시간에서의 domain-shift를 고려하고, 예측 신뢰도로 도메인 차이를 근사화하려고 합니다. 데이터 증강은 오류 누적을 줄이기 위해 도메인 차이가 큰 경우에만 적용되도록 수식이 작성되어있습니다.

- `\tilde y'_t ^T` : Augmentation-averaged prediction from the teacher model
- `\hat y'_t ^T` : Direct prediction from the teacher model
- `conf(f_{\theta_0}(x _t ^T)` : The source pre-trained model's prediction confidence on the current input `x _t ^T`
- `p_{th}` : A confidence threshold
식 (4)를 통해 사전 학습 모델을 이용해 현재 입력에 대한 prediction confidence을 계산하여 소스와 현재 도메인 사이 도메인 차이를 근사화하는 시도를 해볼 수 있다. confidence(신뢰도)가 낮을수록 도메인 갭이 더 크다는 것을 나타내고, 상대적으로 높은 confidence 수준은 도메인 갭이 더 작다는 것을 의미한다고 가정한다. 그러므로 신뢰도가 높고 임계값보다 큰 경우에는 어떠한 augmentation도 사용하지 않고 의사 레이블로 `\hat y'_t^T`를 직접 사용하기로 한다.
만약 신뢰도가 낮으면 의사 라벨 품질을 더 향상시키기 위해 추가로 `N`개의 무작위 증강을 적용합니다. 도메인 갭이 작은 신뢰할 수 있는 샘플(confident samples)에 대해서 랜덤 증강을 적용하면 가끔 모델 성능 저하를 일으키기도 합니다.
요약하자면, Confidence를 Domain difference를 근사화하는데 사용하였고, 언제 Augmentation을 사용해야하는지를 결정했습니다. Student는 refined 의사 라벨로 업데이트됩니다.
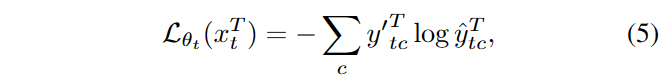
Stochastic Restoration
적절한 의사 레이블은 오류 축적을 줄이는 데 도움이 될 수 있지만, Continual adaptation by self-training for a long time은 오류 발생과 망각의 위험을 내포합니다. 특히, 데이터 시퀀스에서 강력한 도메인 변화가 일어날 때 이 문제는 더욱 심각해질 수 있습니다. Strong Domain-shift는 예측이 잘못 보정되거나 오류를 야기할 수 있으며, 이로 인해 자가 훈련은 잘못된 예측을 더욱 강화하는 부작용을 가져올 수 있습니다. 어려운 데이터 포인트를 처리한 후에는, 비록 새로운 데이터가 크게 변하지 않더라도, 지속적인 적응으로 인해 모델이 이전의 잘못된 학습으로부터 회복하지 못할 수도 있습니다.
Catastrophic forgetting : 모델이 새로운 데이터에 지속적으로 적응하려고 할 때 이전에 학습한 정보를 빠르게 잊어버리는 현상으로 특히 연속적인 데이터 스트림을 처리할 때 나타나며, 특정 데이터나 도메인에 과도하게 적응함으로써 모델이 이전에 학습한 유용한 정보를 상실하게 만듭니다.
이에 Source pre-trained model로부터 지식을 명시적으로 복원하는 Stochastic resotration 방법을 제안합니다.
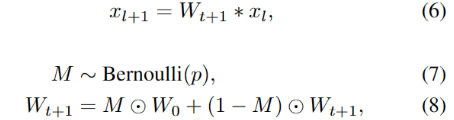
- `x_l` & `x_{l+1}` : the input and output to this layer
- `W_{t+1}` : trainable convolution filters
- `p` : small restore probability
- `M` : mask tensor of the same shape as `W_{t+1}`
- mask tensor는 `W_{t+1}` 내에서 소스 가중치 `W_0`으로 다시 복원할 요소를 결정한다.
Stochastic restoration은 Dropout의 특별한 형태라고 볼 수 있습니다. 훈련 가능한 가중치의 일부 텐서 요소를 확률적으로 초기 가중치로 복원함으로써 네트워크는 초기 소스 모델에서 너무 멀리 떨어지는 것을 막아 catastrophic forgetting을 방지합니다. 그리고 소스 모델의 정보를 보존함으로써 모델 붕괴 없이 훈련 가능한 모든 매개변수를 훈련할 수 있게 됩니다.

알고리즘 1에서 볼 수 있듯 refined 의사 레이블과 확률론적 복원을 결합하면 CoTTA 기법이 탄생함.
EXPERIMENTS
5 Continual test-time adaptation benchmark tasks
- Image Classification
- CIFAR10-to-CIFAR10C (standard & gradual) with WideResNet-28
- CIFAR100-to-CIFAR100C with ResNeXt-29
- ImageNet-to-ImageNet-C
- Semantic Segmentation
- Cityscapses-to-ACDC
4.1 Datasets and tasks
5 Severities 15 Corruptions 32 Augmentations and each corruptions have 10,000 images.
CIFAR
"Online continual test-time adaptation task" 상황에서 CIFAR10 또는 CIFAR100에서 사전 학습된 모델을 사용하는 경우, 데이터가 테스트 단계에서 'online' 방식으로 모델에 들어오게 됩니다. 이 때 데이터는 'Corrupted images'로, 여러 왜곡(corruptions)이 적용된 이미지들입니다.
이 과정에서 데이터가 모델에 입력되는 방식에는 크게 두 가지 패턴이 있습니다
기존 TTA 방식은 각 corruption 타입마다 Indivisually 입력에 들어왔는데, 여기선 Sequentially 들어오게 된다.
- Individually:
- 이 방식에서는 각 왜곡 유형(corruption type)의 이미지 배치가 개별적으로 처리됩니다. 즉, 한 가지 유형의 왜곡이 적용된 모든 이미지가 모델에 입력되고, 해당 왜곡에 대한 적응이 완료될 때까지 계속해서 같은 유형의 왜곡 이미지가 모델에 제공됩니다.
- 한 왜곡 유형의 처리가 끝나면, 그 다음 왜곡 유형으로 넘어가서 동일한 과정을 반복합니다.
- Continually Sequentially :
- 반면에, 다양한 Corruption 유형의 이미지가 연속적이고 순차적으로 모델에 입력됩니다.
- 이 경우, 모델은 한 Corruption 유형에서 다른 유형으로 부드럽게 전환하면서 지속적으로 적응합니다. 한 유형이 끝나고 다른 유형이 시작되어도, 모델은 중단 없이 연속적으로 적응 과정을 진행합니다.
> 실험 결과
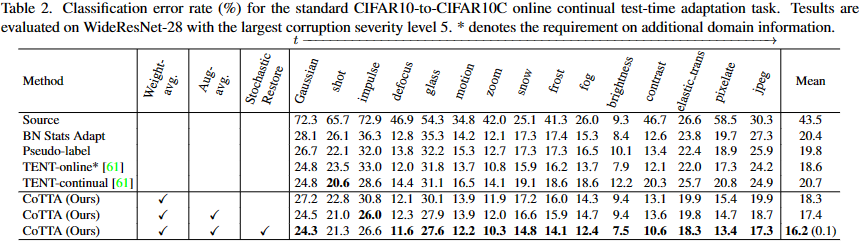
- BN Stats Adapt : uses the Batch Normalization statistics from the input data of the current iteration. simple and fully online. Source 대비만 봐도 성능 확 차이남
- hard pseudo-labels : update BN-trainable parameters
- TENT-Online : 새로운 도메인을 감지할 때 모델을 원래의 사전 훈련된 상태로 초기화
- "access to the additional domain informain"은 새로운 도메인 즉, 각 Corruption이 시작되는 시점에 대한 얘기같음
- 하지만 현실 세계에서 이런 정보가 주어질리가 없기 때문에 동적인 환경에선 좋은 성능을 보이기 힘들 것임
- (참고) 코드에서는 기본적으로 Online TENT로 설정되어 있기 때문에
- TENT-Continual : 새로운 도메인이 시작되는 시점을 알지 못하고, 연속 데이터 스트림을 처리하면서 계속 적응함
- Online에서 말하는 추가적인 도메인 정보가 없기 때문에 BN Stats Adapt에 비해 좋은 성능을 보여주지 못함
- 처음 3개 Stage에 대해서만 성능이 크게 개선되긴 했지만, 그 이후로는 성능 저하가 급격했음
- 즉, 이 말은 TENT는 Error Accumulation으로 인해 장기간 지속 적응에 대해 불안정함을 나타낸다고 할 수 있다.
- CoTTA : 대부분의 Corruption에서 좋은 성능을 보여주었음
- Stochastic restore approach 덕분에 장기 관점에서 성능 저하가 발생하지 않았다고 주장함
- Gradually changing setupt
- Standard 환경에선 가장 높은 단계의 Severity에서 Corruption이 급격하게 변함
- Continual한 평가를 위해 Gradual도 추가하였고, 단계별로 아래와 같은 스텝이 진행된다.
- Distribution shift도 gradual하게 변할 것임
- 손상 유형 `t`에 대해 무작위로 섞인 10개의 시퀀스를 만든 다음 전체 대한 평균 오류율을 계산한다.
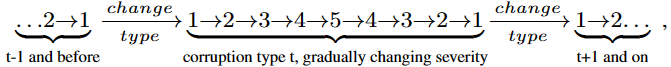

Conclusion
- Firstly, we reduced the error accumulation by using weight-averaged and augmentation-averaged predictions which are often more accurate.
- Secondly, to preserve the knowledge from the source model, we stochastically restored a small part of the weights to the source pre-trained weights.
- The proposed method can be incorporated in off-the-shelf pre-trained models without requiring any access to source data



댓글