📑Document/Test-Time Adaptation
PR-3 / RoTTA : Robust Continual Test-time Adaptation
Introduction
- DA와 DG는 distribution shift 문제를 해결하기 위해 제안되었으나, raw source data에 대한 접근이 필요함
- 하지만 대부분의 현실 시나리오는 데이터 보호 규정으로 인해 원시 데이터를 공개적으로 사용할 수 없어야함
- 또한, 기존 방법들은 Backward 계산량이 많아 학습 비용이 감당할 수 없을 만큼 높아짐
- TTA는 레이블이 지정되지 않은 테스트 데이터 스트림만 사용하여 테스트 시간에 온라인으로 distribution shift 문제를 해결하고자 함
- 명백히 말해서 TTA는 Visual Recognition, Multi-modality, Document understanding 등 다양한 분야에서 주목받음
- Prior TTA 연구 대부분은 테스트 샘플이 고정된 Target domain에서 독립적으로 샘플링되는 간단한 시나리오에 집중함
- 그러나 테스트 환경이 자주 변경되면 이러한 가정이 쉽게 위반될 수 있음
- 이후에는 LAME, NOTE와 같은 방법론에선 테스트 샘플 내의 시간적 상관 관계를 고려하기 시작했음
- 가령, 자율주행에서는 자동차가 고속도로에서 더 많은 차량을 따라가거나 거리에서 더 많은 보행자를 만나기 때문에 테스트 샘플은 시간이 지남에 따라 높은 상관 관계를 가진다.
- 보다 현실적으로 날씨, 위치 또는 기타 요인에 대한 주변 환경의 변화에 따라 데이터 분포가 바뀔 수 있다.
- 한마디로 현실에서는 분포 변화와 데이터 상관 관계가 동시에 일어남을 의미함
- 지속적으로 변화하는 Distribution에 직면하면 pseudo-labeling 또는 Entropy minimization과 같은 기존 알고리즘은 error gradients가 누적됨에 따라 더욱 신뢰할 수 없게 된다.
- 게다가 테스트 샘플 간의 높은 상관 관계로 인해 배치 정규화에 대한 통계의 잘못된 추정 및 모델 붕괴가 발생함
- the High correlation → the erroneous estimation of statistics for batch normalization and collapse of the model.
- 이 분석에 따라 이러한 데이터 스트림에 적응하는 것은 두 가지 주요 한계점에 직면하게 된다.
- 배치 정규화 통계의 잘못된 추정은 테스트 샘플의 잘못된 예측으로 이어져 결과적으로 잘못된 적응을 야기함
- 모델은 correlative sampling으로 인해 발생한 분포에 쉽게 또는 빠르게 과적합됨
- 따라서 이러한 역동적인 시나리오는 Robust adaptation을 위한 새로운 TTA 패러다임을 요구하고 있다.
- 본 작업에서는 테스트 단계에서 distribution changing과 correlative sampling이 동시에 발생하는 보다 현실적인 TTA 상황을 가정한다.
- 저자는 이를 Practical Test-Time Adaptation (PTTA)라고 명명한다.
- PPTA와 이전 설정 간의 유사점과 차이점을 명확하게 이해하고싶다면 Figure 1과 Table 1을 참고.
- 이 어려운 문제를 해결하기 위해 Robust Test-Time-Adaptation, RoTTA 방법을 제안한다.
- Robust statistics estimation
- Timeliness와 Uncertainty을 고려한 Category-balanced sampling
- Time-aware Robust Training
- 먼저 현재 배치의 잘못된 통계를 exponential moving average에 의해 유지되는 global statistics로 대체
- BatchNorm 레이어의 통계를 추정하는 것보다 안정적인 방법임
- 그런 다음 버퍼링된 샘플의 timeliness와 uncentainty을 고려하면서 Category-balanced sampling을 사용하여 메모리에 있는 유사-독립적인 데이터 배치를 시뮬레이션한다.
- 즉, 더 새롭고 덜 불확신한 샘플들이 더 높은 우선 순위로 메모리에 보관됨
- 카테고리가 균형을 이루고 적시에 신뢰할 수 있는 샘플 배치를 통해 현재 분포의 스냅샷을 얻을 수 있음
- 마지막으로, robust adaptation을 수행하는 교사-학생 모델을 사용하여 메모리 뱅크에 있는 샘플의 적시성을 고려하는 Time-aware reweighting 전략을 소개한다.
- 광범위한 실험을 통해 RoTTA가 PTTA와 같은 실제 설정에 강력하게 적응할 수 있음을 보여줌
- 간단히 말해서(In a nutshell), 본 논문의 Contribution은 다음과 같다.
- 분포 변화와 상관관계 샘플링을 모두 고려하여 실제 애플리케이션에 더 적합한 PTTA 설정을 제안
- PTTA 상황에서 이전 방법들의 성능을 벤치마킹하고 문제의 한 측면만 고려하여 비효율적인 적응을 초래한다는 점을 발견함
- PTTA 상황을 보다 포괄적으로(compregensive) 고려하는 RoTTA을 제안함. (구현이 쉽고 효율적?)
- CIFAR-10-C 및 CIFAR-100-C와 대규모 DomainNet 데이터셋에서 기존 모델 대비 좋은 성능을 보여줌
- 각각 5.9%, 5.5%, 2.2% 이상 오류를 줄임
2. Related Work
Domain Adaptation (DA)
- DA는 레이블이 지정된 소스 데이터 셋에서 학습된 지식을 레이블이 없는 타겟 데이터셋으로 전이하는 문제를 다룸
- 대표적인(representative) 기술로는 Latent distribution alignmet, Adversarial learning, Self-training이 있음
- 그러나 이 가정의 한계는 훈련 시 레이블이 지정된 훈련 데이터(Source Domain) 외에 레이블이 지정되지 않은 테스트 데이터(Target Domain)가 필요하다는 점
- 따라서 Test-time adaptation과 같이 보다 실용적인 시나리오를 다루지 못한다.
- PTTA 설정은 즉석에서 샘플 적응을 상호 연관적으로 수행하는 것으로 볼 수 있음
- 여러 대상 도메인의 연속적인 데이터 스트림에만 액세스할 수 있는 경우 일반적인 도메인 적은 기술이 무너질 수 있음
Domain Generalization (DG)
- DG는 모델 훈련에 여러 소스 도메인을 사용할 수 있다고 가정하고, 본 적 없는 도메인에 대해 일반화를 잘 할 수 있는 모델을 학습려고 함
- Data Augmentation, Meta-learning, 또는 Domain Alignment을 기반으로 한 방법론들이 주를 이루고있음
- 반면, PTTA는 지속적으로 변화하는 여러 타겟 도메인의 레이블이 지정되지 않은 온라인 데이터 스트림을 사용하여 테스트 시 사전 훈련된 소스 모델의 성능을 향상시키는 것을 목표로 한다.
Continual Learning (CL)
- 지속적 학습은 Incremental learning 또는 Life-long learning이라고도 불림
- 이는 이전 작업에서 얻은 지식을 잊지 않고, 여러 작업에 대한 모델을 순차적으로 학습하는 것을 목표로 함
- Replay-based, Regularization-based의 방법으로 기법에 따라 분류됨
- 지속적인 학습에 대한 아이디어는 Continuous Domain adaptation 방식에도 적용된다.
- CL과 마찬가지로 PTTA도 Catastrophic forgetting을 겪는 다는 점을 지적하여 TTA 접근 방식을 불안정하게 만듬
- CF : 보통 Correlation sampling으로 인해 CF가 발생해 새로운 테스트 샘플에 대한 성능 저하가 발생함
Test-time Adaptation (TTA)
- TTA은 소스 모델과 레이블이 지정되지 않은 대상 데이터만 사용할 수 있는 보다 까다로운 상황에 집중함
- 유사한 패러다임은 Soure-Free Domain Adaptation, SFDA으로 훈련 데이터에 대한 접근이 필요하지 않음
- SHOT : Self-supervised pseudo-labeling과 Information Maximization을 사용하여 Soure Hypothesis를 조정함
- TENT : source pre-trained model을 가져와서 Entropy minization을 사용하여 Batch-Norm 레이어에서 일부 훈련 가능한 매개변수를 업데이트하여 이를 테스트 데이터에 적용
- 표준 TTA가 많은 작업에서 널리 연구되었지만 Distribution shift(changing)과 Data correlation sampling이 모두 분리되어 고려되어왔다는 사실은 여전히 남아 있음
- 3D semantic segmentation[63], Test-time prompt tuning[64], Video segmentation[82]
- NOTE [19] : correaltively sample test streams의 문제를 해결하기 위해 IABN과 PBRS을 제안했지만, 지속적으로 변화하는 분포에 대한 장기적인 적응에 대해선 여전히 불안정하다는 점을 고려하지 않았음
- CoTTA [73] : 타겟 테스트 데이터는 지속적으로 변화하는 환경에서 스트림되고 기성 pre-trained model을 현재 테스트 데이터에 지속적으로 적용한다고 가정함
- 저자는 이러한 Continual Test-time adaptation 상황에서 Distribution changing과 Correlation sampling 상황을 모두 고려한 보다 실용적인 TTA 설정인 PTTA를 다루기로 함
3. Method
3.1. Problem Definition and Motivation
- Source Domain $\mathcal{D}S={(x^S,y^S)}$으로부터 pre-trained된 model : $f{\theta_0}$ with parameter $\theta_0$
- PTTA의 목표는 $f_{\theta_0}$이 주어지면 $f_{\theta_0}$을 Online으로 레이블이 없는 샘플 $\mathcal{X}_0,\mathcal{X}_1,...;,\mathcal{X}_T$의 스트림에 적용하는 것임
- 여기서 $\mathcal{X}t$는 시간 $t$에 따라 지속적으로 변하는 분포 $\mathcal{P}{test}$의 correlated가 높은 샘플 배치
- 구체적으로는 Test-time에서 시간이 지남에 따라 테스트 분포 $\mathcal{P}_{test}$는 $\mathcal{P}_0,\mathcal{P}_1,...;,\mathcal{P}_\infin$으로 지속적으로 변함
- 시간 단계 $t$에서 라벨이 지정되지 않은 correlated sample 배치 $\mathcal{X}t$를 $\mathcal{P}{test}$로부터 받게 됨
- 그 다음 $\mathcal{X}t \to f{\theta_t}$ 로 입력되면, 모델은 현재 테스트 데이터 스트림에 적응하고, 즉석에서 $f_{\theta_t}(\mathcal{X}_t)$를 예측해야함
- 실제로 위 문제 상황은 주로 동적 시나리오에서 모델을 배포하는 실제 요구 사항에 따라 결정됨
- 앞서 언급한 자율주행의 경우를 예로 들면, 테스트 샘플은 높은 상관관계를 갖고 있으며 날씨나 위치에 따라 데이터 분포가 지속적으로 변경된다.
- 또 다른 예는 지능형 모니터링의 상황인데, 카메라는 퇴근 후와 같은 특정 시간에 지속적으로 더 많은 사람을 캡처하지만 근무 시간 중에는 더 적은 수의 사람을 지속적으로 캡처한다.
- 동시에 조명 상태는 낮부터 밤까지 계속해서 변한다.
- 배포된 모델은 이러한 동적 시나리오에 강력하게 적용되어야 함
- 한마디로 현실 세계에서는 distribution change와 data correlation가 동시에 일어나는 경우가 많음
- 이러한 이유로 기존 TTA 방법은 동적 시나리오에서 테스트 스트림을 샘플링할 때 불안정해질 수 있음
- PTTA의 테스트 스트림을 얻기 위해 테스트 샘플 간의 상관 관계를 시뮬레이션하기 위해 매개변수 $\delta$을 사용하여 Dirichlet distribution을 채택했음
- CIFAR-10-C 데이터셋에서 다양한 $\delta$ 값에 해당하는 테스트 데이터 스트림을 제시
- $\delta$가 작을 수록 Correltation이 높아짐
- 통일성을 위해 모든 실험에서 $\delta=0.1$을 기본값으로 설정했음
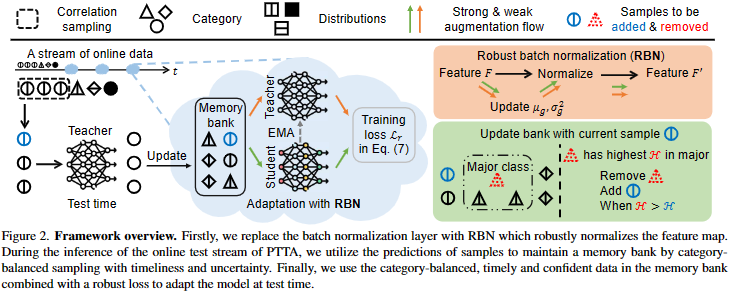
기존 BatchNormalization layer를 Feature map을 강인하게 정규화하는 RBN으로 대체함
PTTA의 온라인 테스트 스트림을 추론하는 동안, 샘플 예측을 활용하여 적시성과 불확실성을 갖춘 카테고리 균형 샘플링을 통해 메모리 뱅크를 유지
마지막으로, 테스트 시간에 모델을 적응하기 위해 robust한 loss와 결합된 메모리 뱅크의 카테고리 균형을 이루고 시의 적절하며 신뢰할 수 있는(confident) 데이터를 사용함
3.2. Robust Test-Time Adaptation
- 이전 TTA 방법에서 일반적으로 사용된 현재 배치 데이터의 통계가 Correlation 테스트 데이터 스트림을 만날 때 신뢰할 수 없게 된다는 사실에 동기를 받아, 먼저 정규화를 위해 robust한 Global statistics를 사용한다.
- 그런 다음, 현재 데이터 분포에 효과적으로 적응하기 위해, 적시성(Timeliness)와 불확실성을 고려하여 카테고리 균형 샘플링을 통해 메모리 뱅크를 유지한다. 이 방법은 분포의 보다 안정적인 상태를 포착하는 스냅샷을 기록한다.
- Timelineness : 데이터 스트림이 지속적으로 변화하므로, 모델이 이러한 변화에 신속하게 반응하여 새로운 정보를 학습할 수 있도록 함
- Uncertainty : 데이터 포인트들이 가지는 예측의 확실성 또는 불확실성을 고려. 일부 데이터 포인트는 불확실성이 높아 모델이 이를 학습하는 데 방해가 될 수 있음
- Snapshot : 사전적으로 데이터의 특정 시점에서의 상태나 모습을 기록한 것을 의미하며, 여기선 데이터 흐름(스트림) 속에서 특정 시점의 데이터 분포를 잘 나타내는 대표적인 데이터 포인트들의 집합
- 마지막으로, Teacher-Student 모델을 활용하고 모델을 강력하게 훈련시키기 위해 timeliness-based reweightning 전략을 설계했음. (적시성 기반의 재가중 전략?)
Robust batch normalization (RBN)
- Batch Normalization은 gradient explosion and vanishing을 줄여 네트워크의 훈련 및 수렴 속도를 가속화하고, 훈련 과정을 안정화할 수 있기 때문에 널리 사용되는 훈련 기술 중 하나임
- 훈련 시 BN 레이어에 대한 입력으로 Feature map $F\in\mathbb{R}^{B\times C\times H\times W}$가 주어지면, 채널 별 평균 $\mu\in\mathbb{R}^C$ 및 분산 $\sigma^2\in\mathbb{R^C}$는 다음과 같이 계산된다.
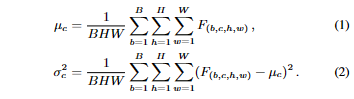
- 그런 다음 Feature map은 다음과 같이 채널 방식으로 정규화되고 정제된다.
- the feature map is normalized and refined in a channel-wise manner as
- 여기서 $\gamma,\beta\in\mathbb{R}^C$는 레이어에서 학습 가능한 매개변수이고 $\epsilon>0$은 0이 되지 않도록 안정성을 위한 상수임
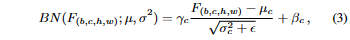
- the feature map is normalized and refined in a channel-wise manner as
- 한편, 훈련 중에 BN 레이어는 추론을 위해 global running mean and variance ($\mu_S,\sigma^2_S$) 그룹을 유지함
- 테스트 시 발생하는 domain-shift로 인해 전역 통계 ($\mu_S,\sigma^2_S$) 가 테스트 기능을 부정확하게 정규화하여 심각한 성능 저하를 초래할 수 있음
- 이 문제를 해결하기 위해 일부 방법은 현재 배치의 통계를 사용하여 정규화를 수행하기도 함 [55, 70, 73]
- 하지만 테스트 샘플이 PTTA 설정에서 높은 상관 관계를 가지면 Figure 4c에서 볼 수 있듯이 현재 배치의 통계도 feature map을 올바르게 정규화하지 못함.
- 특히 BN [53]의 성능은 데이터 상관 관계가 증가함에 따라 급격히 감소함
- 일련의 분석을 바탕으로 Feature map을 강력하게 정규화하기 위해 Global statistics group ($\mu_g,\sigma^2_g$) 을 유지하도록 하는
**Robust BN (RBN)**모듈을 제안한다.- test-time adaptation 전에, ($\mu_g,\sigma^2_g$) 는 사전 훈련된 모델의 running mean and variance ($\mu_S,\sigma^2_S$)으로 초기화됨
- 모델을 조정할 때, Exponential Moving Average (EMA)을 사용하여 global statistics를 먼저 업데이트
- 여기서 ($\mu, \sigma^2$)는 메모리 뱅크에 버퍼링된 샘플의 통계값을 의미
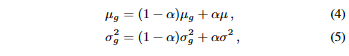
- 그런 다음 식 (3)을 이용하여 feature를 정규화고 affine시킴.
- 테스트 샘플을 추론할 때, Global statistics group ($\mu_g,\sigma^2_g$) 을 직접 활용하여 식 (3)과 같이 출력을 계산함
- 일련의 과정이 간단해보이지만, RBN은 PTTA 테스트 스트림의 정규화 문제를 해결하는 데 충분히 효과적임
Category-balanced sampling with timeliness and uncertainty (CSTU)
- CSTU 접근 방식은 PTTA 설정에서 데이터 샘플 간의 상관관계를 고려한다.
- 시간 $t$에서 실시간으로 입력되는 테스트 샘플들 $\mathcal{X}t$ 사이 correlation은 시간에 따라 관찰된 분포 $\widehat{\mathcal{P}}{test}$와 실제 테스트 분포 $\mathcal{P}_{test}$ 사이의 편차를 초래할 수 있음
- 구체적으로, 관찰된 marginal label 분포 $p(y|t)$는 전체 레이블 분포 $p(y)$와 다를 수 있음
- 시간이 지남에 따라 $\mathcal{X}t$와 지속적으로 학습하는 것은 신뢰할 수 없는 분포 (unreliable distribution) $\widehat{\mathcal{P}}{test}$에 모델을 적응시킬 수 있으며, 이는 효과적이지 않은 적응과 모델 붕괴의 위험이 높아질 수 있음⇒ 실제 테스트 데이터의 분포가 시간이 지남에 따라 변할 수 있으며, 모델이 이러한 변화를 정확히 반영하지 못하면 적응 과정에서 잘못된 방향으로 학습될 수 있습니다. 이로 인해 모델의 일반화 능력이 떨어지고, 극단적인 경우에는 모델이 완전히 잘못된 패턴을 학습하여 붕괴할 수 있음을 얘기하는 것
- ⇒ 모델이 지속적으로 입력 데이터에 적응하는 과정에서 신뢰할 수 있는 데이터 분포를 유지하는 것이 중요함을 인지!
- 이러한 문제를 해결하기 위해, Category-balanced Memory bank $\mathcal{M}$을 제안한다.
- 업데이트 시 샘플의 적시성과 불확실성을 고려하는 $\mathcal{N}$ 용량의 memory bank $\mathcal{M}$
- 여기서 $\mathcal{M}$의 업데이트를 가이드하기 위해 pseudo-labels를 채택함
- 카테고리 간 균형을 위해, $\mathcal{M}$의 용량을 각 카테고리에 균등하게 분배하고 주요 카테고리 샘플을 먼저 교체
- 한편, 지속적으로 변화하는 테스트 분포로 인해 $\mathcal{M}$의 이전 샘플은 값이 제한되고, 모델이 현재 분포에 적응하는 기능이 손상될 수 있음. 게다가 불확실성이 높은 샘플은 항상 모델 모델 적응을 방해할 수 있는 잘못된 기울기 정보 (erroneous gradients information)을 생성함
- 이를 염두에 두고 (with this in mind), $\mathcal{M}$의 각 샘플을 heuristics ($\mathcal{A,U}$)와 연결
- $\mathcal{A}$는 샘플의 수명 ( 0으로 초기화되고, 시간 $t$에 따라 증가함)
- $\mathcal{U}$는 예측에 대한 엔트로피로 계산된 불확실성
- 그리곤 적시성과 불확실성을 결합하여 경험적 점수(heuristic score) 즉, 적시성과 불확실성을 갖춘 카테고리 균형 샘플링을 아래와 같이 계산한다.
- 여기서 $\lambda$는 전부 1.0으로 설정되어있어서 신경 안써도 될 듯
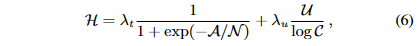
- CSTU를 사용하면 현재 테스트 분포 $\mathcal{P}_{test}$에 대한 robust snapshot을 얻을 수 있으며, 이에 모델을 효과적으로 적응시킬 수 있을 것임
[보충]메모리 뱅크는 적시성과 불확실성을 고려하여 관리되며, 테스트 샘플들의 예측에 기반하여 업데이트됨- 여기서 적시성은 메모리 뱅크에 오래 머문 시간을 나타내고, 불확실성은 예측의 엔트로피로 계산됨
- 메모리 뱅크 관리 : 메모리 뱅크는 $\mathcal{N}$개의 용량을 가지고 있으며, 각 카테고리 별로 균등하게 용량을 배분하여 각 카테고리에서 중요한 샘플들을 보존함
- 샘플의 시간 가중치 : 각 샘플은 ($\mathcal{A,U}$) 쌍의 휴리스틱과 함께 메모리 뱅크에 첨부되며, 여기서 $\mathcal{A}$는 샘플의 나이(메모리 뱅크에 머문 시간)을 나타내고 $\mathcal{U}$는 예측의 엔트로피를 통해 계산된 불확실성을 나타냄
- 휴리스틱 점수 계산 : 적시성과 불확실성을 고려하여 휴리스틱 점수 $\mathcal{H}$를 계산. 이는 샘플을 메모리 뱅크에 추가하거나 제거하는 데 사용됨
- 여기서 $\lambda_{t}$와 $\lambda_{u}$는 각각 적시성과 불확실성에 대한 가중치를 결정하는 파라미터이고, C는 클래스의 개수
- 이 식은 샘플이 현재 분포를 얼마나 잘 반영하는지(적시성)와 예측의 불확실성을 얼마나 갖고 있는지를 종합적으로 평가하여 점수를 부여함
- $\mathcal{H} = \lambda_{t} \frac{1}{1 + exp(-A/N)} + \lambda_{u} \frac{U}{log C}$
Robust training with timeliness
- 실제로 BN 레이어를 RBN으로 교체하고, CSTU를 통해 선택된 메모리 뱅크를 얻은 후 의사 라벨링 또는 엔트로피 최소화와 같이 널리 사용되는 기술을 직접 채택하여 TTA를 수행할 수 있음
- 하지만! Category balance를 유지하는 것이 최우선 사항이였기 때문에 너무 오래되었거나 신뢰할 수 없는 인스턴스도 여전히 $\mathcal{M}$에 머물 수 있는 기회가 있음을 알 수 있음
- 게다가 모델을 너무 공격적으로 업데이트하면 $\mathcal{M}$의 카테고리 균형이 불안정해져 적응도 불안정해짐
- 심지어는 distribution 변화로 인한 error accumulation으로 인해 앞서 언급한 접근 방식도 동작하지 않게 됨
- 오래되고 신뢰할 수 없는 인스턴스에 대한 error gradients information의 위험을 더욱 줄이고, 적응을 안정화하기 위해 robust한 unsupervised leaning 방법으로 teacher-student model을 채택하기로 했으며, timeliness reweighting 전략을 제안한다.
- 또한, 시간 효율성과 안정성을 위해 적응 중에는 RBN의 아핀 매개변수만 훈련됨
- Update process
- Model Update : 시간 $t$에서, 선생 모델 $f_{\theta^T_t}$를 사용하여 상관 데이터 $\mathcal{X}t$를 추론한 후, 교사 모델 $f{\theta^T_t}$와 메모리 뱅크 $\mathcal{M}$를 사용하여 학생 모델 $f_{\theta^S_t}$을 업데이트한다
- Student model loss 최소화 : 학생 모델의 파라미터 $\theta_S$는 다음 손실을 최소화하여 업데이트됨
- 여기서 $\Omega$는 메모리 뱅크의 총 용량, $x_i^M$는 메모리 뱅크 내 인스턴스, $\mathcal{A}_i$는 인스턴스의 나이를 의미
- $L_r = \frac{1}{\Omega} \sum_{i=1}^{\Omega} L(c_i, x_i^M; A_i; \theta_T, \theta_S)$
- Teacher model update : 교사 모델 파라미터 $\theta_T$는 $EMA$를 사용하여 업데이트됨
- $\theta_T^{t+1} = (1 - \nu)\theta_T^t + \nu\theta_S^{t+1}$
- 여기서 $\nu$는 update rate
- Timeliness re-weighting : 메모리 뱅크의 인스턴스 손실 값을 계산하기 위해, 적시성 재가중치 $E(\mathcal{A}_i)$이 계산됨
- $E(A_i) = \frac{exp(-A_i/N)}{1 + exp(-A_i/N)}$
- 여기서 $\mathcal{A}_i$는 인스턴스의 나이, $\mathcal{N}$는 메모리 뱅크의 용량
- Cross-Entropy : 학생 모델로부터 강하게 증강된 $x''_i$의 softmax prediction $p_S(y|x''_i)$와 교사 모델로부터 약하게 증강된 $x'_i$의 prediction $p_T(y|x'_i)$ 사이 cross-entropy를 계산함
- $l(x'i, x''_i) = - \frac{1}{C} \sum{c=1}^{C} p_T(c|x'_i) log; p_S(c|x''_i)$
- 최종 Loss : Timeliness re-weighting와 Cross-Entropy를 결합하여 최종 손실 함수를 구함
- $L_r(x_i^M; \mathcal{A}_i; \theta_t^T, \theta_t^S) = E(\mathcal{A}_i)l(x'_i, x''_i)$
⇒ 메모리 뱅크를 통해 데이터의 최신 상태를 반영하고, 적시성과 불확실성을 고려하여 학생 모델을 지속적으로 업데이트한다. 이는 동적 시나리오에서 사전 훈련된 모델을 효과적으로 적응시킬 수 있는 방법으로서 제안되었음

Category-balanced sampling with timeliness and uncertainty (CSTU)를 한 테스트 샘플에 대해 수행하는 과정
테스트 시간 동안 메모리 뱅크를 관리하는 알고리즘
- 입력 : 테스트 샘플 $x$, 교사 모델 $f_{\theta^T}$
- 정의 : Memory bank $\mathcal{M}$, its capacity $\mathcal{N}$, 클래스 개수 $\mathcal{C}$, 클래스 마다 점유율 $\mathcal{O}\in\mathbb{R}^C$, 전체 점유율 $\Omega$, Classes to pop instance $\mathcal{D}$?
- 추론 : $p(y|x)=\text{Softmax}(f_{\theta^T}(x))$ : 교사 모델을 사용하여 샘플 $x$의 예측된 클래스 확률 $p(y|x)$ 계산
- Predicted category of $x$ ⇒ $\hat y=\arg\max_cp(c|x)$ : 확률 $p(c|x)$이 가장 높은 클래스
- Uncertainty ⇒ $\mathcal{U}x=-\sum^C{c=1}p(c|x)log(p(c|x))$ : 예측된 클래스 확률에 기반한 엔트로피로 계산
- The age ⇒ $\mathcal{A_x}=0$
- The Heuristic score ⇒ $\mathcal{H}x = \lambda{t} \frac{1}{1 + exp(-A/N)} + \lambda_{u} \frac{U}{log C}$
- 과정
- 메모리 뱅크 업데이트
- 만약 샘플 $x$의 클래스 $\hat y$의 현재 점유율이 용량 $\mathcal{N}$ 미만이면, $\mathcal{D}$는 빈 집합
- 그렇지 않다면, $\mathcal{D}$는 클래스 $\hat y$에서 가장 낮은 휴리스틱 점수를 가진 샘플 집합
- 새로운 샘플 추가 또는 교체
- $\mathcal{D}$가 비어 있으면, 샘플 $x$를 메모리 뱅크 $\mathcal{M}$에 추가
- $\mathcal{D}$가 비어 있지 않으면, $\mathcal{D}$ 안의 샘플 중 휴리스틱 점수가 $\mathcal{H}_x$가 가장 높은 샘플을 찾은 다음, $\mathcal{H}_x$가 기존 샘플의 휴리스틱 점수보다 크면 기존 샘플을 메모리 뱅크 $\mathcal{M}$에서 제거하고 새 샘플을 추가
- 샘플 무시 또는 보존
- 만약 새 샘플 $x$의 휴리스틱 점수가 $\mathcal{D}$ 안의 샘플보다 낮으면, 샘플 $x$를 무시
- 그렇지 않으면, 샘플 $x$를 메모리 뱅크에 추가
- 모든 인스턴스의 연령 $\mathcal{A}$ 증가
- 메모리 뱅크 $\mathcal{M}$에 있는 모든 샘플의 연령을 증가시킴
- 메모리 뱅크 업데이트
Framework overview explanation
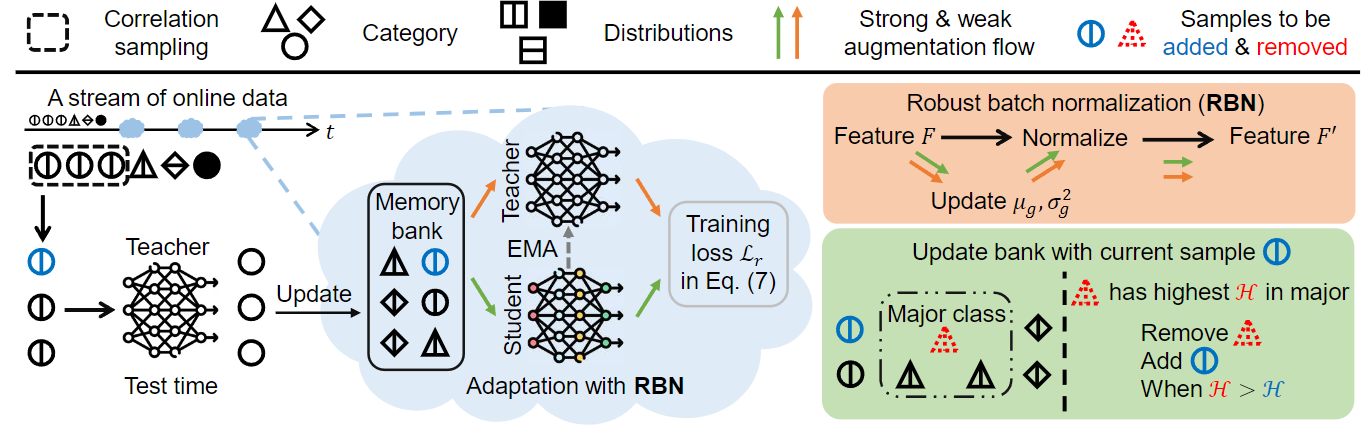
- Target data input
- 시간 $t$에서 실시간(Online)으로 들어오는 데이터 스트림 $\mathcal{X}t$에 대해 교사 모델 $f{\theta_T}$이 expectation을 수행
- 시간 $t$에서 실시간으로 입력되는 테스트 샘플들 $\mathcal{X}t$ 사이 correlation은 시간에 따라 관찰된 분포 $\widehat{\mathcal{P}}{test}$와 실제 테스트 분포 $\mathcal{P}_{test}$ 사이의 편차를 초래할 수 있음⇒ 실제 테스트 데이터의 분포가 시간이 지남에 따라 변할 수 있으며, 모델이 이러한 변화를 정확히 반영하지 못하면 적응 과정에서 잘못된 방향으로 학습될 수 있음
- 이러한 문제를 해결하기 위해, Category-balanced Memory bank $\mathcal{M}$을 제안함
- ⇒ 모델이 지속적으로 입력 데이터에 적응하는 과정에서 신뢰할 수 있는 데이터 분포를 유지하는 것이 중요함을 인지
- 시간 $t$에서 실시간으로 입력되는 테스트 샘플들 $\mathcal{X}t$ 사이 correlation은 시간에 따라 관찰된 분포 $\widehat{\mathcal{P}}{test}$와 실제 테스트 분포 $\mathcal{P}_{test}$ 사이의 편차를 초래할 수 있음⇒ 실제 테스트 데이터의 분포가 시간이 지남에 따라 변할 수 있으며, 모델이 이러한 변화를 정확히 반영하지 못하면 적응 과정에서 잘못된 방향으로 학습될 수 있음
- 시간 $t$에서 실시간(Online)으로 들어오는 데이터 스트림 $\mathcal{X}t$에 대해 교사 모델 $f{\theta_T}$이 expectation을 수행
- Correlation Sampling
- 실시간으로 들어오는 데이터 스트림에서, 특정 시간 $t$에 상관 관계가 있는 레이블이 없는 데이터 샘플들 $\mathcal{X}_t$을 선택
- 데이터의 시간적 연속성을 반영, 데이터 간 상관 관계를 고려하여 샘플링을 진행
- Initial Teacher Frame work $f_{\theta_0}$ update
- 선택된 샘플들은 교사 모델에 입력됨
- 교사 모델은 이 샘플들을 사용하여 현재의 데이터 분포를 기반으로 한 예측을 수행
- Test-Time
- 교사 모델에 의한 Expectation은 test-time 동안 발생하며, 이 예측 결과는 모델이 새로운 데이터에 어떻게 반응해야 하는지를 결정하는데 사용함
- Update
- 교사 모델로부터 얻은 정보는 학생 모델을 업데이트하는 데 사용함
- 학생 모델이 시간에 따라 변하는 데이터 분포에 지속적으로 적응할 수 있도록 도움
- Memory Bank
- 선택된 샘플들을 저장하는 데 사용됨
- 학생 모델이 과거 데이터를 참고하여 현재 데이터에 대한 예측의 정확도를 높이는 데 도움



댓글