[PR-1] R-CNN : Rich feature hierarchies for accurate object detection and semantic segmentation
Object Detection
R-CNN은 Object Detection 분야에 딥러닝을 최초로 적용시킨 모델이자 이전의 Object Detection 모델들과 비교해 성능을 상당히 향상시킨 모델이다. Object Detection이란 Single Object가 아닌 Multiple Objects에 대해 어떤 물체인지 Class로 분류하는 Classification, 그 물체가 어디 있는지 Bounding Box를 통해 위치 정보를 나타내는 Localization을 모두 포함한다.
- Object Detection = Multi-Labeled Classification + Bounding Box Regression(Localization)
Object Detection은 AlexNet(2012) 이후 R-CNN(2014)과 YOLO(2016)의 등장으로 크게 1-stage Detector와 2-stage Detector로 구분할 수 있다.
- 1-stage Detector : Classification과 Localization의 두 Task를 동시에 처리하는 방법
- YOLO > SSD > RetinaNet > SqueezeDet > CornerNet (
YOLO 계열과 SDD 계열) - 비교적 빠르지만 정확도가 낮다.
- YOLO > SSD > RetinaNet > SqueezeDet > CornerNet (
- 2-stage Detector : Classification과 Localization의 두 Task를 순차적으로 처리하는 방법
- R-CNN > SPPNet > Fast R-CNN > Faster R-CNN > Mask R-CNN > FPN (
R-CNN 계열이 대표적) - 비교적 느리지만 정확도가 높다.
- R-CNN > SPPNet > Fast R-CNN > Faster R-CNN > Mask R-CNN > FPN (

R-CNN
R-CNN : 'Regions with Convolutional Neuron Networks features'
설정한 Region을 CNN의 Feature(입력값)로 활용하여 Object Detection을 수행하는 신경망을 의미한다.
R-CNN의 기본 구조는 2-stage Detector로 전체 Task를 두 단계로 나눌 수 있다.
- 물체의 위치를 찾는 Region Proposal
- 물체를 분류하는 Region Classification
위 두 가지 Task를 처리하기 위해 수행되는 R-CNN의 구조를 알아보자.
- Region Proposal : 물체의 영역을 Detection
- Pre-trained CNN : Proposal된 영역에서 고정된 크기의 Feature Vector를 Wraping/Crop하여 CNN의 입력으로 사용
- Pre-trained CNN from ImageNet
- SVM, Support Vector Machine :
- CNN으로부터 나온 Feature Map을 활용하여 Linear Supervised Learning Model, SVM을 활용한 분류 작업
- Bounding Box Regression : Regression을 통한 Bounding Box 구분
1.Region Proposal
Data와 Label을 입력으로 넣으면, R-CNN은 일반적으로 이미지를 Data로 사용하며, Label은 정답 Bounding Box를 주게된다. 이미지 픽셀들을 Vertex로 표현하여 데이터 형식으로 나타낼 수 있다. (vertex 간의 연결고리를 Edge로 부름)
결국 R-CNN은 이런 Image Data를 입력받아서 Object Detection&Classification을 **잘**하는 Bounding Box를 찾는 것이 목적이라 할 수 있겠다.
R-CNN은 "Selective Search"라는 알고리즘을 이용해서 임의의(Auxiliary) Bounding Box를 설정한다.
Selective Search는 Segmentation 분야에 많이 쓰이는 알고리즘이며, Object와 주변간의 색감(Color), 질감(Texture) 차이, 다른 물체에 둘러 쌓여 있는지 여부 등을 파악해서 인접한 유사 픽셀끼리 묶어 물체의 위치를 파악할 수 있도록 한다.
- Selective Search Algorithm :
1) Small Random Bounding-Box를 많이 생성
2) 이러한 Bounding-Box들은 hierarchical Grouping Alogrithm을 사용해 조금씩 Merge
3) 이를 바탕으로 ROI, Regions of Interest를 제안하는 Region Proposal 형식으로 진행된다.

Vertex : 하늘 색 원Component : Vertex들이 연결되어 있는 덩어리Segment : Component에서 의미있는 영역
여기서 main 수식을 살펴보자.
- $Dif(C_1, C_2)$ = C1과 C2간의 차이 (Component 외부의 계산값)
- $MInt(C_1, C_2)$ = C1 내부에서의 어떤 값과 C2 내부에서의 값을 계산한 값 (Component 간의 내부 계산값)
위 두 값을 비교해서 Dif 값이 더 크면 두 Component(영역)을 그대로 놔두고, MInt 값이 더 크면 두 Component를 Merge하게 된다. 이러한 수식을 통해 나오는 여러 Segment된 이미지들을 Hierarchical Grouping Algorithm을 사용해서 Merge하는 것이다. Merge하여 구한 Region Proposal된 영역 즉, ROI를 CNN의 입력값으로 넣어주는 것이다.
2. CNN
CNN은 Input값의 크기가 고정되어있기 때문에 다양한 사이즈로 생성된 Bounding Box를 같은 사이즈 (227x227)로 통일시키는 작업을 진행한다. → Warping
본 논문에서는 Pre-trained AlexNet의 구조를 그대로 사용했으며, Object Detection을 위해 마지막 부분만 수정했다고 한다.
3. SVM, Support Vector Machine
CNN 모델로부터 Feature가 추출이 되고 Training Label이 적용되면 Linear SVM을 이용하여 Classification 작업을 진행한다. SVM은 기계학습 분야에서 Pattern Recognition 또는 Data Anyalistic에 사용되는 Supervised Learning Model로 주로 Classification이나 Regression Analysis을 위해 사용된다.
참고로 R-CNN에서 Classifier로 Softmax를 사용하지 않고 SVM을 사용한 이유는 Softmax를 사용했을 때 mAP 값이 50.9%로 더 떨어졌기 때문이라고 한다.
4. BBR, Bounding Box regression
 |
 |
|---|

Selective Search로 찾은 Bounding Box 위치가 부정확하기에 Bounding Box Regression을 시행한다.
Bounding Box 위치 선정을 교정하고 모델의 성능을 높이기 위한 과정이라고 생각하자.
- Bounding Box Regression을 통해서 나온 값을 CNN 단계 전으로 전달하여 Region Proposal이 더 잘 되도록 한다.
Ground truth, G와 Initial Bounding Box, P의 위치는 중심점 좌표 (x, y)와 Box의 크기 (Width, Height)를 결합하여 표시할 수 있다.
- P : 처음 Region Proposal을 통해서 제안된 Bounding Box
$P^i = (P^i_x, P^i_y, P^i_w, P^i_h) $ - G : Ground Truth Bounding Box, 정답 박스
$G = (G_x, G_y, G_w, G_h)$
즉, P(x, y, w, h)가 입력으로 들어왔을 때 이를 이동시켜 G를 잘 예측하는 것이 목표 (P를 정답 G에 맞추기)
Bounding Box의 Input값은 N개의 Training Pairs로 이루어져 있다.
d 함수는 P를 $\hat{G}$으로 이동시키기 위해 필요한 이동량을 의미하며, BBR에서 학습시키는 것이 이 d함수이다.
t 함수는 P를 G로 이동시키기 위해 필요한 이동량을 의미하며, d함수와 형태는 동일하다.
Loss Function은 "MSE of t and d" + "L2 normalization"을 추가한 형태.
- $P_x$ update : $\hat{G_x} = P_wd_x(P)+P_x$ → $d_x$는 x에 대한 Transformation 함수를 의미한다.
- $P_y$ update : $\hat{G_y} = P_hd_y(P)+P_y$ → $d_y$는 y에 대한 Transformation 함수를 의미한다.
- width와 height는 지수 함수를 통해서 업데이트가 된다
Summary
So what is R-CNN?
Image InputRegion proposal
→ Selective search Algorithm을 통해 ROI를 2000여 개 정도의 Region을 봅아내어 Bounding Box를 생성Warping
→ CNN에 입력으로 넣기 위해 Bounding Box의 크기를 227x227로 압축(Warping)시킨다.
→ Bounding Box size의 비율을 고려하지 않기 때문에 이 과정에서 Original Input Image가 왜곡되고 정보가 소실된다.CNN Feature Extract
→ Warped Bounding Box를 CNN 모델에 넣어 Pre-Trained CNN Model(from ILSVRC2022) Object Detection 용으로 Fine-Tuning을 진행Image Classfication with SVM
→ CNN을 통해 추출한 Feature을 가지고 Class 별로 SVM Classfier를 학습시킨다.
→ SVM Classification을 거치면 2000여 개의 Bounding Box들은 각각 어떤 물체일 확률 값을 가진다.Non-Maximum Suppresion
→ 2000여 개의 Bounding Box는 어떤 Object일 확률 값을 가지지만, 이 Boxes를 모두 사용하지 않는다.
→ 이런 경우 NMS를 사용해 객체 전체를 대상화할 수 있는 Bounding Box 한 개를 선택한다.Bounding Box Regression
→ Selective Search로 찾은 Bounding Box의 위치가 부정확하기에 BBR을 시행한다.
→ Bounding Box의 위치 선정을 교정하고, 모델의 성능을 높이기 위한 과정이다.
Limitations
- AlexNet을 그대로 사용하기 위해 Image를 강제로 변형해야한다.
- Warping하는 과정에서 Input 이미지가 왜곡되고 정보 소실이 발생한다.
- Selective Search를 통해 뽑힌 2000여 개의 Region Proposal 후보를 모두 CNN에 집어넣기 때문에 Training / Testing Time이 오래 걸린다.
- Selective Search나 SVM이 GPU에 특화되어 있지 않다.
- Computing Sharing이 일어나지 않는다. 즉, CNN / SVM / BBR 총 세 가지 모델이 결합된 End-to-End 훈련이 불가능하다.
R-CNN Paper
22 Oct 2014
Abstract
본 논문에서는 mAP 53.3%의 성능을 보여준 Detection 알고리즘을 제안한다.
Approach : (1)high-Capacity CNN을 사용, (2) 레이블 훈련 데이터가 부족한 경우, 보조 작업에 대한 사전 지도학습을 진행하고, 도메인 별 Fine-tuning을 진행하면 성능이 크게 향상된다.지역 제안을 CNN과 결합하기 때문에 이 모델을 R-CNN:Regions with CNN feature라고 한다.
그리고 R-CNN과 유사한 CNN 구조로 만들어진 Sliding-window Detector인 OverFeat와 R-CNN을 비교한다.
R-CNN은 200개 클래스로 이루어진 ILSVRC2013 Detection dataset에서 OverFeat를 훨씬 능가한 성능을 보여줬다.
1. Introduction
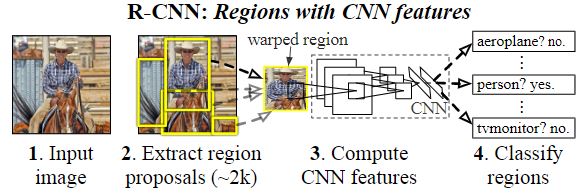
(1) 입력 이미지가 들어오면 약 2000개의 상향식 영역 제안을 추출
이미지 입력
댓글