💻 Dev/Code Review
[pytorch] TENT : Fully Test-time Adaptation with Entropy Minimization
reference.
논문 출처: Tent: 엔트로피 최소화를 통한 완전한 테스트 시간 적응 | OpenReview
코드 출처: DequanWang/tent: ICLR21 텐트: 엔트로피 최소화를 통한 완전한 테스트 시간 적응 (github.com)
prerequisite
episodic은 각 데이터 배치(episode)마다 어떻게 adaptation시킬 건인지를 결정하는 데 사용된다.
- episodic=True : 모델은 각 에피소드(데이터 배치 또는 시간 단위 등) 후에 사전에 저장된 초기 상태로 복원된다. 이는 모델이 이전 데이터의 영향을 받지 않고 각 새로운 에피소드에서 처음부터 시작하도록 한다. Datastream이 서로 독립적인 경우에 사용한다. 가령, 각 에피소드가 서로 다른 환경이나 조건에서 샘플링된 데이터를 포함하는 경우, 모델이 이전 에피소드의 데이터로부터 영향을 받지 않도록 하는 것이 중요할 수 있다.
- episodic=False : 반면에, 이 경우 모델은 계속해서 이전 데이터의 학습 결과를 바탕으로 적응을 지속한다. 이는 _Continual Datastream에서 모델이 지속적으로 적응하는 방식_이다. 모델은 지속적으로 데이터에서 학습하고, 이전 배치의 학습 결과를 다음 배치의 학습에 활용하여 적응 능력을 강화한다.
code review. I [tent.py]
import torch
import torch.jit
import torch.nn as nn
from copy import deepcopy- deepcopy는 파이썬의 copy 모듈에 있는 함수로 객체를 복사할 때 사용하는 라이브러리
- 원본 객체의 모든 요소를완전히 새로운 복제본으로 만들어준다. (원본 객체와 복제본이 서로 독립적으로 동작하도록)
- 이 코드에서는 모델과 옵티마이저의 상태를 완전히 독립적인 복제본으로 만들어주는 데 사용 중이다.
- 이렇게 하면 원본 모델과 옵티마이저의 상태는 변경되지 않고 복제본에서만 업데이트가 이루어지도록 할 수 있음
class Tent(nn.Module):
def __init__(self, model, optimizer, steps=1, episodic=False):
super().__init__()
self.model = model
self.optimizer = optimizer
self.steps = steps
assert steps > 0, "tent requires >= 1 step(s) to forward and update"
self.episodic = episodic
self.model_state, self.optimizer_state = \
copy_model_and_optimizer(self.model, self.optimizer)
def forward(self, x):
if self.episodic:
self.reset()
for _ in range(self.steps):
outputs = forward_and_adapt(x, self.model, self.optimizer)
return outputs
def reset(self):
if self.model_state is None or self.optimizer_state is None:
raise Exception("cannot reset without saved model/optimizer state")
load_model_and_optimizer(self.model, self.optimizer,
self.model_state, self.optimizer_state)- def __init__(self, model, optimizer, steps=1, episodic=False)
- steps : 모델이 각 입력에 대해 적응을 수행하는 횟수를 결정한다. → 최소값 1 이상
- episodic : 모델이 에피소드별로 리셋되어야 하는지를 결정한다.
- 모델과 옵티마이저의 상태를 복사하여 저장합니다. 이는 추후에 모델을 초기 상태로 복원하는 데 사용된다.
- def forward(self, x)
- 입력 데이터 `x`에 대해 모델을 실행하고 적응
- episodic가 True인 경우, 모델을 초기 상태로 리셋
- 지정된 steps 횟수만큼 forward_and_adapt 함수를 반복하여 실행
- def reset(self)
- 모델과 옵티마이저를 저장된 초기 상태로 복원
@torch.jit.script
def softmax_entropy(x: torch.Tensor) -> torch.Tensor:
"""Entropy of softmax distribution from logits."""
return -(x.softmax(1) * x.log_softmax(1)).sum(1)- @torch.jit.script
- torch의 Just-In-Time(JIT) 컴파일 기능을 사용하여 코드를 최적화하여 _실행 시간을 단축_시킬 수 있음
- def softmax_entropy(x: torch.Tensor) -> torch.Tensor
- softmax의 entropy를 계산하는 함수로 이는 "torch.Tensor" 타입의 객체를 반환한다.
- return (Shannon entropy)
- x.softmax(1) : 입력 `x` logit에 대해 소프트맥스를 적용하여 확률 분포를 얻음
- x.log_softmax(1) : 입력 `x`에 로그 소프트맥스를 적용함
- 여기서 구현된 entropy 계산식은 `text{Shannon entropy}`를 사용한 수식 (아래 논문 일부 발췌)
- `H(\hat y)=-sum_c p(hat y_c)log p(hat y_c)`
- 여기서는 모델이 얼마나 "확신"을 가지고 예측하는지를 나타내는 지표로 사용됨

deepl is broken
@torch.enable_grad()
def forward_and_adapt(x, model, optimizer):
# forward
outputs = model(x)
# adapt
loss = softmax_entropy(outputs).mean(0)
loss.backward()
optimizer.step()
optimizer.zero_grad()
return outputs- def forward_and_adapt(x, model, optimizer)
- 테스트 시간에서 모델을 데이터에 적응시키는 과정을 구현한 함수
- 모델에 입력 데이터(`x`)를 제공하고, 모델의 예측에 대한 Entropy를 측정한 후, 이를 바탕으로 모델을 적응시키는 과정을 포함하고 있음
- @torch.enable_grad()
- Test stage에도 기울기(Gradient)를 계산할 수 있도록 활성화
- 일반적으로 테스트 모드에서는 기울기 계산이 비활성화되지만, 이 경우 모델 적응을 위해 의도적으로 활성화
forward pass
- outputs = model(x)
- 모델에 현재 입력 데이터 `x`를 제공하고, 모델의 예측 결과를 얻음
adapt process
- loss = softmax_entropy(outputs).mean(0)
- 모델의 예측 결과에 대한 엔트로피를 계산하고, 이를 평균하여 손실 값을 얻음
- 해당 `Loss`는 모델의 예측이 가진 불확실성(discrepancy)을 나타내며, 엔트로피를 최소화함으로써 모델의 예측을 더 확실하게 하려는 것을 목적(Objective)으로 함
- loss.backward()
- 손실에 대한 기울기를 계산하고, 이를 모델의 매개변수에 역전파
- optimizer.step()
- 계산된 기울기를 사용하여 모델의 매개변수를 업데이트
- optimizer.zero_grad()
- 다음 반복을 위해 기울기를 초기화
def collect_params(model):
params = []
names = []
for nm, m in model.named_modules():
if isinstance(m, nn.BatchNorm2d):
for np, p in m.named_parameters():
if np in ['weight', 'bias']: # weight is scale, bias is shift
params.append(p)
names.append(f"{nm}.{np}")
return params, names- def collect_params(model)
- 모델에서 Batch Normalization layer의 파라미터를 수집하는 함수
- BN 계층에서 아핀(affine), 스케일(scale)과 시프트(shift) 매개변수를 수집
- 모델에서 Batch Normalization layer의 파라미터를 수집하는 함수
- for nm, m in model.named_modules()
- 모델 내의 모든 모듈을 순회하여 모듈과 그 이름을 반환함
- if isinstance(m, nn.BatchNorm2d)
- 현재 모듈이 2차원 BN 레이어인지 확인
- 본 함수는 batchnorms에서 affine scale과 shift 파라이머를 수집하고, 해당 파라미터와 이름을 반환한다.
def copy_model_and_optimizer(model, optimizer):
"""Copy the model and optimizer states for resetting after adaptation."""
model_state = deepcopy(model.state_dict())
optimizer_state = deepcopy(optimizer.state_dict())
return model_state, optimizer_state
def load_model_and_optimizer(model, optimizer, model_state, optimizer_state):
"""Restore the model and optimizer states from copies."""
model.load_state_dict(model_state, strict=True)
optimizer.load_state_dict(optimizer_state)def configure_model(model):
model.train()
model.requires_grad_(False)
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
m.requires_grad_(True)
m.track_running_stats = False
m.running_mean = None
m.running_var = None
return model
def check_model(model):
is_training = model.training
assert is_training, "tent needs train mode: call model.train()"
param_grads = [p.requires_grad for p in model.parameters()]
has_any_params = any(param_grads)
has_all_params = all(param_grads)
assert has_any_params, "tent needs params to update: " \
"check which require grad"
assert not has_all_params, "tent should not update all params: " \
"check which require grad"
has_bn = any([isinstance(m, nn.BatchNorm2d) for m in model.modules()])
assert has_bn, "tent needs normalization for its optimization"- def configure_model
- model.train() : 모델을 최적화를 통해 Entropy 최소화하기 위해 모델을 훈련 모드로 세팅
- model.requires_grad_(False) : 모델이 모든 매개변수에 대한 기울기 계산을 비활성화
- 특정 매개변수만을 업데이트하려고 할 때 불필요한 기울기 계산을 방지함
- for m in model.modules() ...
- 모델의 모든 부분을 순회하면서 배치 정규화 계층을 찾고, 해당 계층에 대해서만 기울기를 활성화한다
- m.track_running_stats = False
- 배치 정규화 계층에서 실행 중인 평균(mean)과 분산(variance)의 tracking을 비활성화
- 일반적으로 BN은 학습 과정에서 각 배치의 평균과 분산을 계산하고, 이를 현재 통계값에 적용함
- 근데 여기서는 False로 지정했으니 이를 추적하거나 업데이트하지 않음
- m.running_mean = None , m_running_var = None
- 현재 실행중인 평균과 분산을 None으로 설정
- 배치 정규화 계층이 현재 배치의 데이터만 사용하여 평균과 분산을 계산함
- 즉, 이전 배치의 데이터에 대한 정보는 사용하지 않고, 각 배치마다 독립적으로 평균과 분산을 계산함
여기서 실행 중인 통계값을 추적한다는 말은 학습 과정에서 계산된 각 배치의 평균과 분산을 시간에 따라 평균화하여 모델의 상태를 저장하는 과정을 의미한다. 계산된 평균과 분산은 이전에 계산된 통계값들과 결합되어, 전체 훈련 데이터셋에 대한 평균적인 평균과 분산을 형성한다. (running statistics)
훈련이 끝난 후 테스트 또는 inference 환경에서는 이 실행 중인 통계값을 사용하여 입력 데이터를 정규화한다.
특히 running_statistics를 추적하는 기능을 비활성화했는데, 모델이 테스트 데이터의 실시간 statistics에 더 집중하도록 만들기 위함이라고 이해가 된다.
code review. II [cifar10c.py]
해당 코드는 CIFAR-10-C 데이터셋에 대한 모델의 Robustness를 평가하는 스크립트를 구현했다.
다양한 타입의 Corruptions와 Severity(심각도)에 대해 모델을 평가하고, Tent를 이용한 TTA 방법론이 있음
def evaluate(description):
load_cfg_fom_args(description)
# configure model
base_model = load_model(cfg.MODEL.ARCH, cfg.CKPT_DIR,
cfg.CORRUPTION.DATASET, ThreatModel.corruptions).cuda()
if cfg.MODEL.ADAPTATION == "source":
logger.info("test-time adaptation: NONE")
model = setup_source(base_model)
if cfg.MODEL.ADAPTATION == "norm":
logger.info("test-time adaptation: NORM")
model = setup_norm(base_model)
if cfg.MODEL.ADAPTATION == "tent":
logger.info("test-time adaptation: TENT")
model = setup_tent(base_model)
# evaluate on each severity and type of corruption in turn
for severity in cfg.CORRUPTION.SEVERITY:
for corruption_type in cfg.CORRUPTION.TYPE:
# reset adaptation for each combination of corruption x severity
# note: for evaluation protocol, but not necessarily needed
try:
model.reset()
logger.info("resetting model")
except:
logger.warning("not resetting model")
x_test, y_test = load_cifar10c(cfg.CORRUPTION.NUM_EX,
severity, cfg.DATA_DIR, False,
[corruption_type])
x_test, y_test = x_test.cuda(), y_test.cuda()
acc = accuracy(model, x_test, y_test, cfg.TEST.BATCH_SIZE)
err = 1. - acc
logger.info(f"error % [{corruption_type}{severity}]: {err:.2%}")- def evaluate(description)
- Load_model : CIFAR-10으로 사전학습된 가중치 체크포인트를 불러와 기본 모델을 로드한다.
- cfg.MODEL_ADAPTAION : 모델이 테스트 데이터에 어떻게 적응할 것인지를 결정하는 설정값
- Source (원본 모델 사용) : TTA를 수행하지 않고, 원본 모델을 그대로 사용함. 이 경우 모델은 학습된 상태 그대로 테스트 데이터에 적용되며, 적응 기법을 사용하지 않게됨. 즉, 모델이 학습 과정에서 얻은 지식만을 사용하여 테스트 데이터를 처리한다고 볼 수 있다.
- Norm (정규화 적응) : 테스트 데이터에 대해 동적으로 정규화를 수행하여 적응시킴. 테스트 데이터의 배치마다 독립적으로 Statistics를 계산하고, 이를 사용하여 데이터를 정규화함.
- Tent (TENT 적응) : Entropy Minimization을 기반으로 하여 TTA를 수행함. 모델의 매개변수를 테스트 데이터에 대해 동적으로 조정하여, 모델의 예측이 불확실성을 최소화하도록함.
- cfg.CORRUPTION.SEVERITY, cfg.CORRUPTION.TYPE : corruptions 유형과 심각도 조합에 따라 평가를 진행
- 각 조합에 대해 모델을 리셋하고, CIFAR-10C 데이터를 로드한 후, 모델의 정확도를 계산함
def setup_source(model):
"""Set up the baseline source model without adaptation."""
model.eval()
logger.info(f"model for evaluation: %s", model)
return model
def setup_norm(model):
"""Set up test-time normalization adaptation.
Adapt by normalizing features with test batch statistics.
The statistics are measured independently for each batch;
no running average or other cross-batch estimation is used.
"""
norm_model = norm.Norm(model)
logger.info(f"model for adaptation: %s", model)
stats, stat_names = norm.collect_stats(model)
logger.info(f"stats for adaptation: %s", stat_names)
return norm_model
def setup_tent(model):
"""Set up tent adaptation.
Configure the model for training + feature modulation by batch statistics,
collect the parameters for feature modulation by gradient optimization,
set up the optimizer, and then tent the model.
"""
model = tent.configure_model(model)
params, param_names = tent.collect_params(model)
optimizer = setup_optimizer(params)
tent_model = tent.Tent(model, optimizer,
steps=cfg.OPTIM.STEPS,
episodic=cfg.MODEL.EPISODIC)
logger.info(f"model for adaptation: %s", model)
logger.info(f"params for adaptation: %s", param_names)
logger.info(f"optimizer for adaptation: %s", optimizer)
return tent_model
def setup_optimizer(params):
"""Set up optimizer for tent adaptation.
Tent needs an optimizer for test-time entropy minimization.
In principle, tent could make use of any gradient optimizer.
In practice, we advise choosing Adam or SGD+momentum.
For optimization settings, we advise to use the settings from the end of
trainig, if known, or start with a low learning rate (like 0.001) if not.
For best results, try tuning the learning rate and batch size.
"""
if cfg.OPTIM.METHOD == 'Adam':
return optim.Adam(params,
lr=cfg.OPTIM.LR,
betas=(cfg.OPTIM.BETA, 0.999),
weight_decay=cfg.OPTIM.WD)
elif cfg.OPTIM.METHOD == 'SGD':
return optim.SGD(params,
lr=cfg.OPTIM.LR,
momentum=cfg.OPTIM.MOMENTUM,
dampening=cfg.OPTIM.DAMPENING,
weight_decay=cfg.OPTIM.WD,
nesterov=cfg.OPTIM.NESTEROV)
else:
raise NotImplementedError- setup_source : 기본 모델을 평가 모드로 설정하여 별도의 Test-time Adaptation, TTA없이 사용한다.
- setup_norm : test-time 정규화 적응을 모델에 적용하여, 각 배치의 독립적인 statistics를 사용해 특성을 정규화한다.
- setup_tent : 모델을 TENT 적응에 필요한 매개변수로 구성하고, 최적화를 위한 optimizer를 설정한다.
- setup_optimizer는 TENT adaptation에 필요한 Optimizer를 설정하며, practical 환경에서는 Adam 또는 SGD를 사용하길 권장하고 있음. 옵티마이저 세팅은 configure 파일에서 또는 명령어 입력 시 파라미터 입력으로 설정 가능한 모양임
Conclusion
실험 결과는 본 코드가 아닌 CoTTA 논문 오피셜 코드를 사용했다.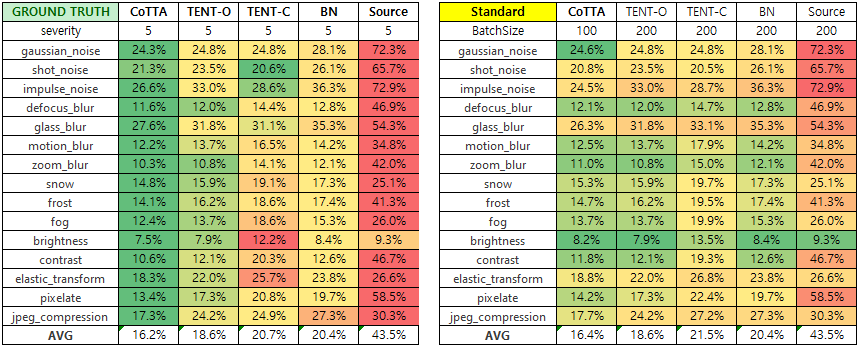
- 서버 컴퓨터 GPU (RTX 3080)의 한계로 CoTTA의 경우 Batchsize를 100으로 낮춰서 진행했다.
- BatchSize를 낮춤으로서 성능 저하가 생겼는데 이는 차후 CoTTA를 리뷰하면서 다시 언급하겠다.
- 코드 Configure에 Episodic 설정하는 부분이 있는데, 이상하게 이 부분을 건들면 성능 저하가 발생했다.
- 그래서 본인은 Episodic은 False 기본값으로 고정하고 TENT-Continual을 평가했다.
서버 GPU 컴퓨터(RTX 3080)가 제약으로 CoTTA의 경우 Batchsize를 100으로 해서 처리했습니다.
댓글